Matthew Beckler's Home Page
:: :: :: :: :: ::
Java Heat Map
Convert Cadence Layout to SVG / PDF / PNG
Makefile -jX setting: How many concurent jobs is optimal?
Infinite Grid of Resistors
How to Start and Stop Folding@Home on OSX
Lego Rendering with POV-Ray
Class Scheduler
Lightsaber Rotoscoping Scripts

Handy Scripts
GPG Tips and Tricks
NCAA Basketball Tournament Data

Isometric Projection in Inkscape
Perspective Motivational Poster
SVG Drawings
SVG Circuit Symbols
Mysterious Textures
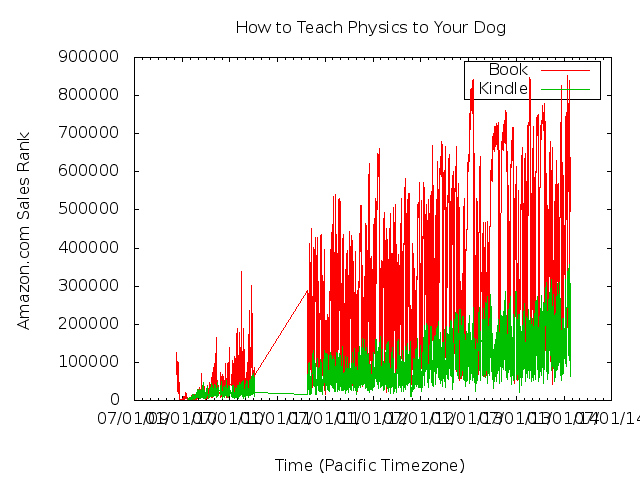
Tracking Amazon.com Sales Rank for
"How to Teach Physics to Your Dog"
A cool guy named Chad Orzel with an interesting blog about physics has written two cool books about teaching physics to your dog. He mentioned that he wanted a system to track the book's sales rank at Amazon.com. Here's a very "quick n' dirty" way to do that. Please note that Amazon changed their page format a while back, and it took me a few months to get it back working again. Sorry for the gap in data.
Current sales rank (book / kindle):
- How to Teach Physics to Your Dog: #637831 / #83413
- How to Teach Relativity to Your Dog: #395542 / #173243

How it works
Update: (2012-02-22) Just added the salesrank trackers for the new book, How to Teach Relativity to Your Dog.
Update: (2010-04-24) After Amazon changed their page format, the old and ugly bash script no longer worked. I replaced it with a nice bit of Python that works much better, and should be more reliable in the future. The script grabs a copy of the book's page at Amazon.com and parses out the sales rank number. This values are appended to a text file and plotted with gnuplot. Times are in the Pacific time zone.
import os, sys, datetime, re
import subprocess
from lxml import etree
def get_pagerank(url):
parser = etree.HTMLParser()
tree = etree.parse(url, parser)
raw = tree.xpath("//li[@id=\"SalesRank\"]/text()")[1]
rank_commas = re.search(".*\#([\d,]*).*", raw)
rank = rank_commas.group(1).replace(",", "")
return rank
os.chdir("/home/mbeckler/mbeckler.org/dog_physics/")
url_book = "http://www.amazon.com/How-Teach-Physics-Your-Dog/dp/1416572287"
url_kindle = "http://www.amazon.com/How-Teach-Physics-Your-ebook/dp/B002ZJCQT2"
url_relativity = "http://www.amazon.com/How-Teach-Relativity-Your-Dog/dp/0465023312"
url_relativity_kindle = "http://www.amazon.com/How-Teach-Relativity-Your-ebook/dp/B0072HV11G/"
#pagerank_book = None
#pagerank_kindle = None
# TODO put this in a while loop with try blocks on the get_pagerank() calls
# or maybe while/try blocks on each page?
# or maybe if not pagerank_book:
#while not pagerank_book and not pagerank_kindle:
pagerank_book = get_pagerank(url_book)
pagerank_kindle = get_pagerank(url_kindle)
pagerank_relativity = get_pagerank(url_relativity)
pagerank_relativity_kindle = get_pagerank(url_relativity_kindle)
datetimestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M")
fid = open("dog_physics_data.txt", "a")
fid.write("%s\t%s\t%s\t%s\t%s\n" % (datetimestamp, pagerank_book, pagerank_kindle, pagerank_relativity, pagerank_relativity_kindle))
fid.close()
# write the current values to a file that is included in the webpage
fid = open("dog_physics_data_current_book.txt", "w")
fid.write("%s" % pagerank_book)
fid.close()
fid = open("dog_physics_data_current_kindle.txt", "w")
fid.write("%s" % pagerank_kindle)
fid.close()
fid = open("dog_physics_data_current_relativity.txt", "w")
fid.write("%s" % pagerank_relativity)
fid.close()
fid = open("dog_physics_data_current_relativity_kindle.txt", "w")
fid.write("%s" % pagerank_relativity_kindle)
fid.close()
subprocess.call(["gnuplot", "dog_physics.gnuplot"])
subprocess.call(["gnuplot", "dog_relativity.gnuplot"])
The script gets called by cron every hour to update the data. I'm not sure how often Amazon updates their values, so this frequency should be matched with their update frequency. There's nothing fancy being done with plotting, so in a few weeks there will probably be too much data to make a nice plot in such a naive way. You can download the raw data below to make your own plots.
Some of the related posts at Uncertain Principles
- Monetizing Neuroses
- Quantization of Books
- Quantization of Books 2: What Does One Sale Get You?
- Move Over, Schrödinger's Cat
- Quantization of Books 3: How Many Books Is That?
Downloads
Download combined data table (txt)
- File format is tab-separated with five fields: datetimestamp physics_salesrank physics_kindle_salesrank relativity_salesrank relativity_kindle_salesrank
- Not all colums are available for the early data points so watch out for that.
- The time format is like this: 20120202_1500, where the time is in Pacific Time.
Download gnuplot script (physics)
Download gnuplot script (relativity)






Copyright © 2004 - 2026, Matthew L. Beckler, CC BY-SA 3.0
Last modified: 2013-02-21 04:14:26 PM (EST)